1. Install Kai
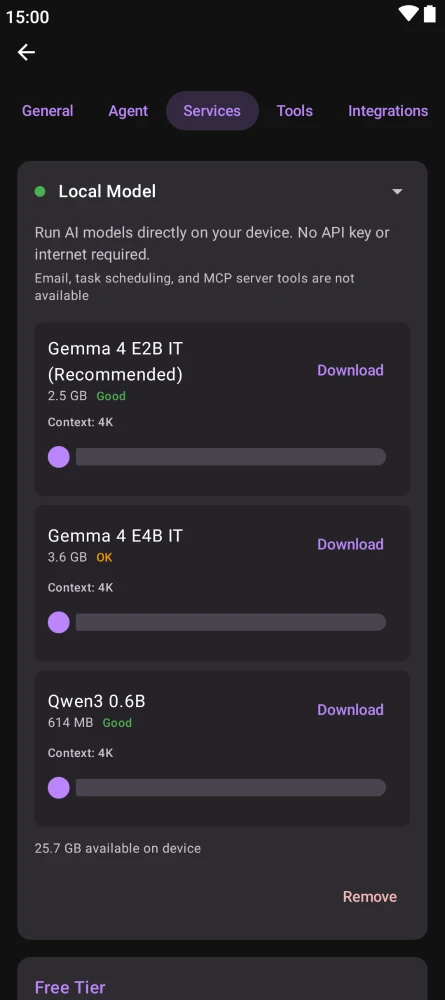
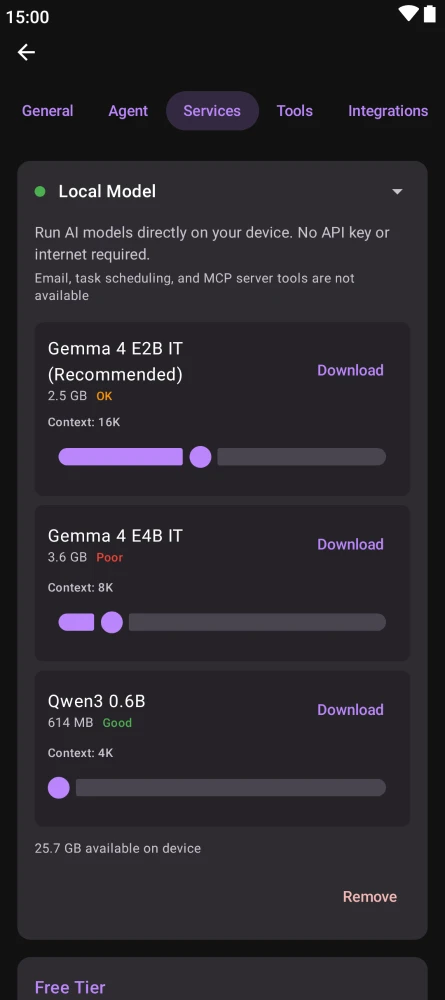
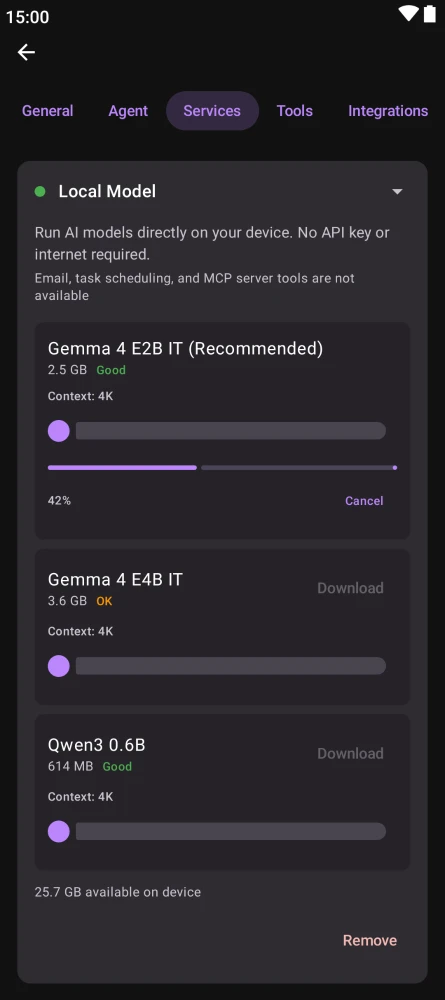
Kai is available on Android (Google Play, F-Droid), desktop (macOS via Homebrew, Windows via Winget, Arch Linux via AUR), and as a downloadable release on GitHub. iOS users can install the app, but on-device Gemma 4 is not yet supported on iPhone — see platform limits below.